Q&A¶
- 如果你刚接触ChubaoFS,希望快速熟悉,请参考 启动docker集群
- 如果你对ChubaoFS感兴趣,希望使用ChubaoFS到您的生产环境,但是又要做性能测试来全方位体验和测评ChubaoFS,请参考 性能评估
- 如果你已经完成对ChubaoFS的测试评估,希望正式投入生产环境,想了解如何进行容量规划及环境配置,请参考 环境及容量规划
- 如果您希望了解ChubaoFS所使用的业务场景,可以参考 使用案例
- 如果您在实际生产环境中遇到了一些问题,不知道如何解决,接下来的内容可能会对你有所帮助。
为了描述方便,定义以下几个关键词缩写
| 全称 | 缩写 | 说明 |
|---|---|---|
| Data Partition | dp | 数据分区 |
| Meta Partition | mp | 元数据分区 |
| Data Partition Replica | dpr | 数据分区副本 |
| Meta Partition Replica | mpr | 元数据分区副本 |
| NodeSet | ns | 节点集 |
| DataNode | dn | 数据节点 |
| MetaNode | mn | 元数据节点 |
编译¶
- 本机编译ChubaoFS,部署到其它机器上无法启动
首先请确认使用 PORTABLE=1 make static_lib 命令编译rocksdb,然后使用ldd命令查看依赖的库,在机器上是否安装,安装缺少的库后,执行 ldconfig 命令
- undefined reference to ‘ZSTD_versionNumber’ 类似问题
可以使用下面两种方式解决
- CGO_LDFLAGS添加指定库即可编译,
例如:
CGO_LDFLAGS="-L/usr/local/lib -lrocksdb -lzstd"这种方式,要求其他部署机器上也要安装zstd库
- 删除自动探测是否安装zstd库的脚本
文件位置示例: rockdb-5.9.2/build_tools/build_detect_platform
删除的内容如下
# Test whether zstd library is installed $CXX $CFLAGS $COMMON_FLAGS -x c++ - -o /dev/null 2>/dev/null <<EOF #include <zstd.h> int main() {} EOF if [ "$?" = 0 ]; then COMMON_FLAGS="$COMMON_FLAGS -DZSTD" PLATFORM_LDFLAGS="$PLATFORM_LDFLAGS -lzstd" JAVA_LDFLAGS="$JAVA_LDFLAGS -lzstd" fi
节点或磁盘故障¶
如果节点或者磁盘发生故障,可以通过decommission操作将故障节点或者磁盘下线。
Datanode/Metanode下线
$ cfs-cli metanode/datanode decommission 192.168.0.21:17210- 什么情况下下线mn/dn?
如果某节点发生了故障无法正常提供服务,为了提升系统可用性而不得不将该节点从集群中摘除,并且让这台机器上的数据自动迁移到其他健康的节点。
- 下线节点后,引起部分节点磁盘io和网络io突然增加
下线操作会触发数据自动迁移,消耗大量网络资源,因此在数据量较大的情况下,请尽量在低峰期进行,并且尽量避免同时下线多台节点。
如何判断下线完成?
$ cfs-cli datapartition check
bad partition ids没有信息,说明下线完成了。
- 常见error1:没有可用的mn,此时所有mn内存或者磁盘已满,需要增加新的mn到集群中
- 常见error2:端口号错误,每台mn的标识符应该是ip+port的组合,port为mn配置文件中的listen端口,不能写错
磁盘下线
如果磁盘发生了故障而节点还能正常提供服务,此时建议你直接下线该磁盘。同样的,和dn/mn下线一样,请尽量在低峰期、避免多次下线操作同时进行。
$ cfs-cli disk decommission { disk } 192.168.0.11:17310
操作正确的话,会提示下线成功,并且该磁盘上的dp均被转移到了其他磁盘。
常见错误和mn/dn下线类似.
data partition/meta partition下线
$ cfs-cli datapartition decommission 192.168.0.11:17310 {Partition ID}
操作正确的话,会提示下线成功,并且该dp被转移到了其他地址。
什么情况下线partition?
- 节点partition过多,下线部分partition减缓压力
- 防止下线节点或磁盘时集群抖动明显
常见错误和mn/dn下线类似
- 如果磁盘写满了,会不会发生爆盘
通常在dn启动参数中建议用户配置disk参数中 {disk path}:{reserved space} 的 reserved space ,防止磁盘写满的情况。当剩余空间小于 reserved space,dn被设置为只读状态,避免了爆盘。
数据及元数据性能¶
- 业务存在大量小文件,元数据规模庞大,怎样提升集群性能
ChubaoFS的元数据存储在内存中,提升mn机身内存或者横向扩展mn节点都会明显提升元数据性能,支撑海量小文件。
- 如果集群中新增了dn/mn,后台是否会自动rebalance,将旧节点上的dp/mp自动转移到新节点?
不会的。考虑到rebalance会增加系统负载,而且增加数据丢失的风险,不会自动rebalance。如果希望新节点能承载更多的dp/mp,分散旧节点压力,可以自行给volume创建dp,或者将旧节点上的dp进行decommission下线操作。
- 有很多批量删除文件的业务造成集群负载过高
设置和查看后台文件删除速率,默认值0,代表不限速。建议设置markdeleterate=1000,然后根据集群中节点的cpu状况动态进行调整。
$ cfs-cli cluster info 查看当前删除限速数值
$ cfs-cli cluster delelerate -h
Set delete parameters
Usage:
cfs-cli cluster delelerate [flags]
Flags:
--auto-repair-rate string DataNode auto repair rate
--delete-batch-count string MetaNode delete batch count
--delete-worker-sleep-ms string MetaNode delete worker sleep time with millisecond. if 0 for no sleep
-h, --help help for delelerate
--mark-delete-rate string DataNode batch mark delete limit rate. if 0 for no infinity limit
容量管理¶
- Volume空间不够用了怎么办?
$ cfs-cli volume expand {volume name} {capacity / GB} 增加volume容量
- 如何提升Volume读写性能?
可读写的dp数量越多,数据就会越分散,volume的读写性能会有响应提升。ChubaoFS采取动态空间分配机制,创建volume之后,会为volume预分配一定的数据分区dp,当可读写的dp数量少于10个,会自动扩充dp数量。而如果希望手动提升可读写dp数量可以用以下命令:
$ cfs-cli volume create-dp {volume name} {number}
一个dp的默认大小为120GB,请根据volume实际使用量来创建dp,避免透支所有dp。
- 如何回收Volume多余的空间
$ cfs-cli volume shrink {volume name} {capacity / GB} 减少volume容量
该接口会根据实际使用量计算,当设定值<已使用量的%120, 操作失败
- 集群空间不够用了怎么办?
准备好新的dn和mn,启动配置文件配置现有master地址即可自动将新的节点添加到集群中。
分区(zone)相关¶
设置集群分区可以防止单个分区故障而引发整个集群不可用。每台节点启动的时候设置 cell 将自动加入该分区。
- 查看分区信息
$ cfs-cli zone list
- 不小心错误设置了volume分区,希望改变分区
$ cfs-cli volume update {volume name} --zone-name={zone name}
- MetaNde和DataNode没有设置分区会怎么样?
集群中大部分参数都是有默认值的,默认分区名字为default。需要注意的是一个分区内必须同时有足够的dn和mn,否则在该分区创建volume,要么数据分片初始化失败,要么元数据分片初始化失败。
- NodeSet的意义?
每个zone会有若干nodeset,每个nodeset的默认容量为18个节点。因为ChubaoFS实现了multi-raft,每个node启动了一个raft server进程, 每个raft server管理该节点上的m个raft实例,如果这些raft实例的其他复制组成员分布在n个node上,raft实例之间会发送raft心跳,那么心跳会在n个节点之间传递,随着集群规模的扩大,n也会变得比较大。而通过nodeset限制,心跳在nodeset内部相对独立,避免了集群维度的心跳风暴,我们是使用了multi raft和nodeset机制一起来避免产生raft心跳风暴问题。
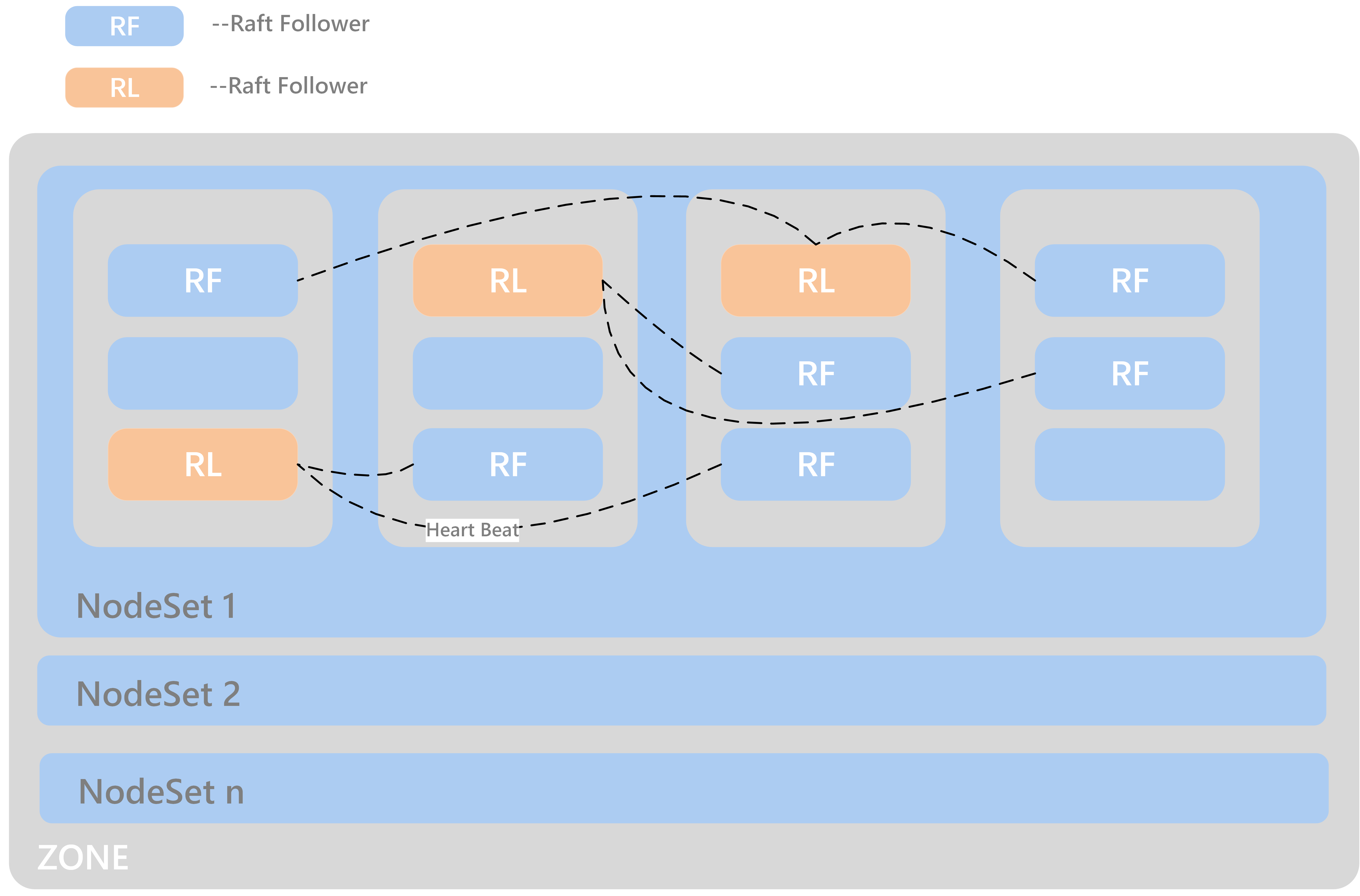
- 一个volume的dp/mp在NodeSet中如何分布?
dp/mp在ns中均匀分布,每创建一个dp/mp,都会从上一个dp/mp所在的ns开始轮询,查找可用的ns进行创建。
- NodeSet数量如何规划?
对于3副本的dp/mp,只有当一个ns中存在至少3个可用节点时,dp/mp才会选择该ns。count(ns) >= 18*n + 3
节点状态异常¶
通过cli工具查看节点状态信息
$ cfs-cli datanode list
[Data nodes]
ID ADDRESS WRITABLE STATUS
7 192.168.0.31:17310 No Inactive
8 192.168.0.32:17310 No Inactive
9 192.168.0.33:17310 Yes Active
10 192.168.0.35:17310 Yes Active
11 192.168.0.34:17310 Yes Active
$ cfs-cli metanode list
[Meta nodes]
ID ADDRESS WRITABLE STATUS
2 192.168.0.21:17210 No Inactive
3 192.168.0.22:17210 No Inactive
4 192.168.0.23:17210 Yes Active
5 192.168.0.25:17210 Yes Active
6 192.168.0.24:17210 Yes Active
- Datanode可写状态 WRITABLE=No 原因排查
- 节点正在等待下线操作完成
- 节点磁盘已满
- 节点刚刚启动正在从本地恢复数据
- Metanode可写状态 WRITABLE=No 原因
- 节点正在等待下线操作完成
- 节点内存空间已经达到totalmemory设定的值已满
- 节点刚刚启动正在从本地恢复数据
- 由三台master组成的集群中坏掉了一台,剩余两台重启能否正常提供服务?
可以。由于Master使用了RAFT算法,在剩余节点数量超过总节点数量50%时,均可正常提供服务。
- 节点 STATUS=Inactive 原因排查
- 节点和master的网络连接中断,需要检查网络状况,恢复网络连接
- 节点进程挂掉,需要查看节点的server进程是否异常终止,此时重启进程即可恢复
系统升级¶
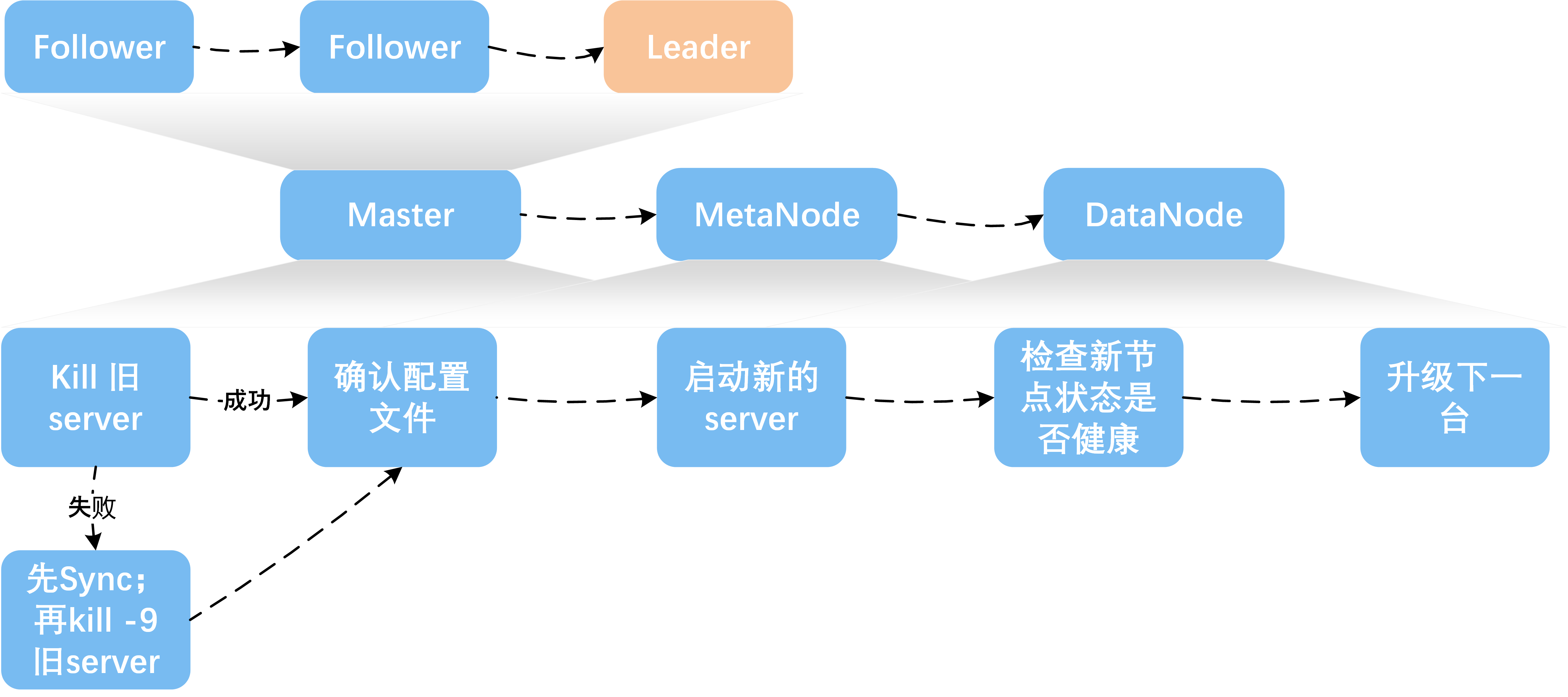
- 升级步骤
- 从ChubaoFS官方网站下载最新二进制文件压缩包https://github.com/chubaofs/chubaofs/releases,解压得到二进制server
- 冻结集群
$ cfs-cli cluster freeze true
- 确认启动配置文件,不要更改配置文件中的数据目录、端口等重要信息
- 停止旧的server进程
- 启动新的server进程
- 检查确认升级后节点状态恢复健康 IsActive: Active
$ cfs-cli datanode info 192.168.0.33:17310 [Data node info] ID : 9 Address : 192.168.0.33:17310 Carry : 0.06612836801123345 Used ratio : 0.0034684352702178426 Used : 96 GB Available : 27 TB Total : 27 TB Zone : default IsActive : Active Report time : 2020-07-27 10:23:20 Partition count : 16 Bad disks : [] Persist partitions : [2 3 5 7 8 10 11 12 13 14 15 16 17 18 19 20]
- 升级下一节点(为了减少对客户端的影响,尤其是在比较大的用户体量下,需要逐一升级MetaNode节点),升级顺序如图所示
- 升级一台Master之后,发现监控系统中没有及时显示?
检查这台master节点的配置信息是否正确,尤其是id号;查看master error日志是否大量报错 no leader,同时在master warn日志中查询关键字leaderChange查看leader变更原因,然后查看raft warn日志进一步分析。
- 升级时能否修改配置文件端口号?
不能,ip+端口号 构成mn和dn实例的唯一标识符,修改之后会被当成新的节点。
在线修改配置¶
- 修改mn threshold
$ cfs-cli cluster set threshold { value }
- 修改集群配置
- 修改volume配置
$ cfs-cli volume set -h
Set configuration of the volume
Usage:
cfs-cli volume set [VOLUME NAME] [flags]
Flags:
--authenticate string Enable authenticate
--capacity uint Specify volume capacity [Unit: GB]
--enable-token string ReadOnly/ReadWrite token validation for fuse client
--follower-read string Enable read form replica follower
-h, --help help for set
--replicas int Specify volume replicas number
-y, --yes Answer yes for all questions
--zonename string Specify volume zone name
- 修改日志级别
提供了在线修改master、MetaNode、DataNode日志级别的接口
$ http://127.0.0.1:{profPort}/loglevel/set?level={log-level}
支持的 log-level 有 debug,info,warn,error,critical,read,write,fatal
离线修改配置¶
- 修改master IP地址
三节点master的ip地址更换之后,需要将所有的mn、dn以及其他引用了master ip地址的应用在修改配置后重启
- 修改DataNode MetaNode端口
不建议修改dn/mn的端口。因为dn/mn在master中是通过ip:port进行注册的。如果修改了端口,master则会认为其为全新节点,旧节点是 Inactive 状态。
- 修改MetaNode totalmemory
Total memory是指MetaNode总内存大小,当MetaNode的内存占用高于此值,MetaNode变为只读状态。通常该值要小于节点内存,如果MetaNode和DataNode混合部署,则需要给DataNode预留内存空间。
- 修改DataNode 保留空间
dn启动配置文件中,disk参数后半部分的数字即为 Reserved Space 值,单位byte,修改完后启动即可。
{ ...
"disks": [
"/cfs/disk:10737418240"
],
...
}
日志处理¶
- 每天产生几十GB日志,占用过多的磁盘空间怎么办?
如果您是开发及测试人员,希望进行调试,可以将日志级别设置为Debug或者info, 如果生产环境,可以将日志级别设置为warn或者error,将大大减少日志的量
$ http://127.0.0.1:{profPort}/loglevel/set?level={log-level}
支持的 log-level 有 debug,info,warn,error,critical,read,write,fatal
- Datanode warn日志
checkFileCrcTaskErr clusterID[xxx] partitionID:xxx File:xxx badCrc On xxx:日志分析:在Master的调度下,dn会每隔几个小时进行crc数据校验。此报错说明crc校验未通过,文件数据出错了。此时需要根据报错信息中的partitionID和File并借助Datanode日志分析文件数据出错的原因。
- Datanode error日志
- Master error 日志
clusterID[xxx] addr[xxx]_op[xx] has no response util time out日志分析:Master向mn或dn发送[Op]命令时响应超时,检查Master和mn/dn网络连通性;查看dn/mn服务进程是否还在。
- Master warn 日志
- Metanode error日志
Error metaPartition(xx) changeLeader to (xx):日志分析:切换leader。正常行为
inode count is not equal, vol[xxx], mpID[xx]日志分析:inode数量不一致。因为写入数据时,三副本中只要有2个副本成功就算成功了,所以会存在三副本不一致的情况。查看日志了解具体原因。
- Metanode warn 日志
- Client warn日志
operation.go:189: dcreate: packet(ReqID(151)Op(OpMetaCreateDentry)PartitionID(0)ResultCode(ExistErr)) mp(PartitionID(1) Start(0) End(16777216) Members([192.168.0.23:17210 192.168.0.24:17210 192.168.0.21:17210]) LeaderAddr(192.168.0.23:17210) Status(2)) req({ltptest 1 1 16777218 test.log 420}) result(ExistErr)日志分析:ExistErr说明在rename操作中,文件名已存在。属于上层业务操作问题。Client运维人员可以忽略此日志。
extent_handler.go:498: allocateExtent: failed to create extent, eh(ExtentHandler{ID(xxx)Inode(xxx)FileOffset(xxxx)StoreMode(1)}) err(createExtent: ResultCode NOK, packet(ReqID(xxxxx)Op(OpCreateExtent)Inode(0)FileOffset(0)Size(86)PartitionID(xxxxx)ExtentID(xx)ExtentOffset(0)CRC(0)ResultCode(IntraGroupNetErr)) datapartionHosts(1.1.0.0:17310) ResultCode(IntraGroupNetErr))日志分析:client向一个mp发送创建extent的请求返回失败,会尝试请求其他mp。
- Client error日志
appendExtentKey: packet(%v) mp(%v) req(%v) result(NotExistErr)日志分析:该错误说明写入文件时文件被删除了,属于上层业务操作问题。Client运维人员可以忽略此日志。
conn.go:103:sendToMetaPartition: retry failed req(ReqID(xxxx)Op(OpMetaInodeGet)PartitionID(0)ResultCode(Unknown ResultCode(0)))mp(PartitionID(xxxx) Start(xxx) End(xxx) Members([xxx xxxx xxxx]) LeaderAddr(xxxx) Status(2)) mc(partitionID(xxxx) addr(xxx)) err([conn.go 129] Failed to read from conn, req(ReqID(xxxx)Op(OpMetaInodeGet)PartitionID(0)ResultCode(Unknown ResultCode(0))) :: read tcp 10.196.0.10:42852->11.196.1.11:9021: i/o timeout) resp(<nil>)日志分析1:client和metanode网络连接异常,根据报错信息“10.196.0.10:42852->11.196.1.11:9021”,检查这两个ip地址之间通路是否正常
日志分析2:检查“11.196.1.11:9021” 上的metanode进程是否挂了
- Raft warn日志
- Raft error日志
raft.go:446: [ERROR] raft partitionID[1105] replicaID[6] not active peer["nodeID":"6","peerID":"0","priority":"0","type":"PeerNormal"]日志分析:该错误是因为网络压力过大而导致延迟增加,超过raft选举时间间隔,raft复制组失去leader。网络恢复后,重新选举leader,该报错会自行消失。
数据丢失及一致性¶
- 单个dn/mn数据全部丢失
该情况可以等同于dn/mn故障,可以通过decommission下线节点,然后重启节点重新注册节点到Master,则Master将其视为新的成员。
- 不小心删除了dn中某个dp目录下的文件数据
dn有自动修复数据的功能,如果长时间数据仍未修复,可以手动重启当前dn进程,会触发数据修复流程。
Fuse客户端问题¶
- 内存及性能优化问题
Fuse客户端占用内存过高,超过了2GB,对其他业务影响过大
离线修改:在配置文件中设置readRate和writeRate参数,重启客户端
在线修改:http://{clientIP}:{profPort} /rate/set?write=800&read=800
Fuse客户端性能优化请参考(https://chubaofs.readthedocs.io/zh_CN/latest/user-guide/fuse.html)
- 挂载问题
- 支持子目录挂载吗?
支持。配置文件中设置subdir即可
挂载失败的原因有哪些
- 挂载失败后,输出以下信息
$ ... err(readFromProcess: sub-process: fusermount: exec: "fusermount": executable file not found in $PATH)查看是否已安装fuse,如果没有则安装
$ rpm –qa|grep fuse yum install fuse
- 检查挂载目录是否存在
- 检查挂载点目录下是否为空
- 检查挂载点是否已经umount
- 检查挂载点状态是否正常,若挂载点 mnt 出现以下信息,需要先umount,再启动client
$ ls -lih ls: cannot access 'mnt': Transport endpoint is not connected total 0 6443448706 drwxr-xr-x 2 root root 73 Jul 29 06:19 bin 811671493 drwxr-xr-x 2 root root 43 Jul 29 06:19 conf 6444590114 drwxr-xr-x 3 root root 28 Jul 29 06:20 log ? d????????? ? ? ? ? ? mnt 540443904 drwxr-xr-x 2 root root 45 Jul 29 06:19 script
- 检查配置文件是否正确,master地址 、volume name等信息
- 如果以上问题都不存在,通过client error日志定位错误,看是否是metanode或者master服务导致的挂载失败
- IO问题
- IOPS过高导致客户端占用内存超过3GB甚至更高,有没有办法限制IOPS?
通过修改客户端rate limit来限制客户端响应io请求频率。
#查看当前iops: $ http://[ClientIP]:[profPort]/rate/get #设置iops,默认值-1代表不限制iops $ http://[ClientIP]:[profPort]/rate/set?write=800&read=800
ls等操作io延迟过高
- 因为客户端读写文件都是通过http协议,请检查网络状况是否健康
- 检查是否存在过载的mn,mn进程是否hang住,可以重启mn,或者扩充新的mn到集群中并且将过载mn上的部分mp下线以缓解mn压力
- 多客户端并发读写是否强一致?
不是。ChubaoFS放宽了POSIX一致性语义,它只能确保文件/目录操作的顺序一致性,并没有任何阻止多个客户写入相同的文件/目录的leasing机制。这是因为在容器化环境中,许多情况下不需要严格的POSIX语义,即应用程序很少依赖文件系统来提供强一致性保障。并且在多租户系统中也很少会有两个互相独立的任务同时写入一个共享文件因此需要上层应用程序自行提供更严格的一致性保障。
- Fsync chunk
- 能否直接杀死client进程,来停止client服务
不建议,最好走umount流程,umount后,client进程会自动停止。